Jupyter Hub Service
Introduction
Warning
This is currently in a testing phase, you may experience issues or data loss and the service is currently provided-as-is with no guarantees.
Please regularly backup your work as Jupyterhub storage may be reset during this phase.
STFC Cloud provides a JupyterHub service for IRIS IAM select group members. This service is available both internally and externally (i.e. without a VPN).
During testing we are primarily to gauging interest and technical feasibility. If you run into any problems, or have any feedback please forward it on using either Slack or the ticketing system (Contact Details)
Advantages
Using the JupyterHub service provides a number of advantages, including:
Access to modern server processing, speeding up reductions
Ability to work without using remote-access onto a desktop
Ability to switch devices and resume work both on-site and off-site
Users without access to powerful compute can process data
After gauging interesting and completing testing we may offer the following further advantages (subject to change):
Instances with a large number of CPU cores
Instances with large memory allocations
Instances with Nvidia GPU Access
Resources Available
As a result of recent limited site access and a hardware installation backlog we are currently providing small Jupyterhub instances.
During testing we plan on measuring node usage to plan future instance sizing.
Storage
Warning
This is not currently backed up and can be lost on service updates/upgrades or unplanned cluster outage. Please keep a copy of any important data locally.
All instances come with a 1GB data store, which is carried between all types. This should be viewed as a working scratch space rather than somewhere to store data long-term.
Lifetime
During our testing phase the lifetime of an instance is 1 day of idle time. After this time period the instance will be stopped, but storage will be retained. On next login the user will be prompted to restart the service.
Available Instances
Default Instance
The default instance comes with the following resources, it’s planned to cover most users requirements:
CPU: 2
RAM: 1.5Gb
Large Memory Instance
This “large” memory instance comes with a larger memory and CPU allowance. It’s planned to cover Jupyter scripts which process large datasets.
CPU: 8
RAM: 7.5GB
GPU Instance
This is not available currently due to pending technical work.
This would provide a dedicated Nvidia GPU instance for users with CUDA/OpenGL workflows.
Switching Instances
To switch between available Instances the original instance must be shutdown:
Complete / Save any work on the existing instance
Go to the top menu-bar -> File -> Hub Control Panel
In the new tab select Stop My Server
You will be returned to the instance selection screen
Any existing storage is automatically transferred between instances
Logging in with IRIS IAM
Account Creation
A IRIS IAM account is required. Help for registering with IRIS IAM can be found here. <https://iris-iam.stfc.ac.uk/help/>
Group Membership
As a individual
Sign into IRIS
Select View Profile Information
The list of groups you belong to is in the top-right, by default this will be empty.
Under Group Requests select, Join a group.
Enter the group name you wish to join and submit. You will need to wait for your group administrator(s) to approve your request.
When the request is accepted the group name will appear in the group list
If you are still unable to access the service contact your group administrator/owner to verify if the group has requested access to Jupyterhub.
As a group administrator/owner
If you’d like to add access to an entire IRIS group please Contact Support with the following, to help us plan capacity:
The IRIS IAM Group name
Estimated number of users
Estimated instance sizes (e.g. we typically use xGB RAM)
Out of Memory Killer
The Out of Memory (OOM) Killer will fire when Python tries to allocate memory, but the instance has run out.
Unfortunately, there is no warning or error, as we require memory (which has run out) to send the message that were out of memory. From a users perspective it will look something like this:
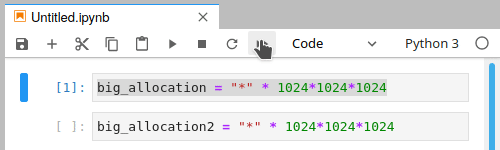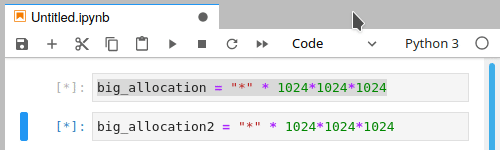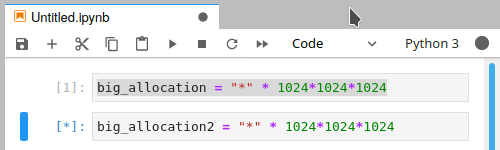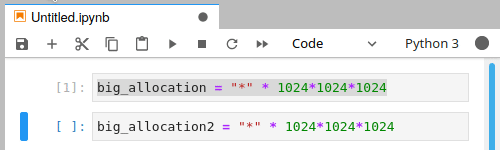
Despite using run all, we have only partially completed the notebook
There will be no * or numeric character next to the cell where we ran out of memory
The Kernel busy indicator (grey circle in top left) will remain busy.
Simply re-running the script will restart Python automatically.
Lowering Memory usage
Unfortunately we are not able to support Python directly, but here are some pointers to help resolve your issue:
Notebooks share memory on an instance once they have been run. These can be shutdown from the top menu-bar -> Kernel -> Shut Down (All) Kernel(s)
Consider the size of the dataset, 100MB of raw data should not saturate a 2GB instance. Equally 10GB of data will require a 16GB instance.
Check for unnecessary copies and duplicated data, for example
raw_data = load_numpy_data()
to_process = raw_data.copy()
processed = my_library.some_operation(to_process)
Depending on how some operation works we could either have 2x or 3x the original data size. Instead we should set these to None after were done to allow Python to clear them. (Note: avoid del, as this could cause bugs later in your program with no added benefit over setting it to None)
raw_data = load_numpy_data()
# Copy was removed and raw_data was passed straight in
processed = my_library.some_operation(raw_data)
# Now we allow Python to garbage collect raw_data
raw_data = None
Advanced users might want to use a memory profiler.
Troubleshooting / FAQ
“I cant launch a notebook”
Notebooks typically take 1-2 minutes to bring your storage online.
If multiple users create instances at roughly the same time it will exhaust our limited number of placeholders and will take the service 10-15 minutes to scale to the new capacity. This will result in a timeout error when creating your service, please retry after 20 minutes.
If you continue to receive timeouts please contact us ( Contact Details) with details of the error you are receiving.
“My notebook randomly stops processing”
Check that your notebook is not being killed by the Out of Memory Killer
Check that your notebook hasn’t entered an infinite loop
Check the Python a library version match your notebook requirements, you may need to pin library versions.
If possible, try testing your notebook locally completes:
If your notebook completes locally please contact us for support
If your notebook fails locally please contact your notebook provider
“I have a problem with my notebook…”
If you suspect there is a problem with your instance please contact us (Contact Details).
Unfortunately the cloud team is unable to provide support for Python problems. Please contact your notebook provider for additional support or consult the Jupyterhub Documentation
Running Own Service
Some understanding of Openstack and Linux CLI usage is required to deploy an instance. User-facing configuration, such as worker flavor, profile sizes / descriptions and GPU support, is written in .yaml files so knowledge of Ansible is not required.
The service is packaged and built specifically for jupyter.stfc.ac.uk out of the box. Variables to control these are split into two files; one for Openstack (number/size of instances…etc.) and one for Jupyterhub (domain name / auth method…etc.).
This allows anybody with access to a Openstack environment with Magnum to run a similar service on any domain.
For requirements, deployment instructions and available features/limitations see the STFC Ansible Jupyter Repository.